Case Study: 2026 Kentucky Derby¶
Result: $85 → $520. Net +$435. MOIC 6.12×. Model picked the winner (Golden Tempo, 25-1).
The first instance of horse-math. Built live with Claude Code in five hours on Derby Day 2026. This document is the frozen artifact, what we did, what the model said, what we bet, what happened, what we learned. Every artifact (code, data, charts, prose) is reproducible from the commit history at main as of May 2, 2026.
For the generalized model that powers future races (Preakness, Belmont, etc.), see the top-level README.md and the src/ directory in its current state.
TL;DR¶
| Race | Kentucky Derby 152, Churchill Downs, May 2, 2026, 1¼ mi |
| Field | 24 entered → 18 ran (6 scratches) |
| Winner | #19 Golden Tempo (Cherie DeVaux, Jose Ortiz), first female trainer to win the Derby |
| Runner-up | #1 Renegade (Pletcher, Irad Ortiz Jr), from post 1, the rail |
| Show | #22 Ocelli (AE that activated) at 70-1 |
| Our top model pick | #19 Golden Tempo, sensitivity scan tagged "ROCK SOLID" |
| Our bet | $85 across win, exactas, trifectas |
| Our hits | $10 win + $2 exacta = $520.06 gross |
| Net P&L | +$435.06 (6.12×) |
| Biggest miss | Trifecta, failed to key #19 on top, missed $5,625 ticket |
1 · Background¶
The seed prompt is preserved in prompts/derby-day.md. Five hours till post when Nigel sat down with Claude Code, no prior infrastructure, no parser, no model, no data. The premise: parse the past performance files, build a feature-scored model, strip the takeout out of the morning line, find horses where our number says the public is wrong. Bet only the overlays. Document the whole thing live, in public.
2 · The Field¶
24 horses entered, 5 scratched before the race, 1 more at the gate. Final field of 18.
Top of the form (entries):
| PP | Horse | Trainer | Jockey | ML | Live |
|---|---|---|---|---|---|
| 1 | Renegade | Pletcher | I. Ortiz Jr | 4-1 | 6-1 |
| 6 | Commandment | Cox | Saez | 6-1 | 5-1 |
| 8 | So Happy | Glatt | Mike Smith | 15-1 | 5-1 |
| 12 | Chief Wallabee | Wm Mott | Alvarado | 8-1 | 7-1 |
| 18 | Further Ado | Cox | Velazquez | 6-1 | 6-1 |
| 19 | Golden Tempo | Cherie DeVaux | J. Ortiz | 30-1 | 25-1 |
Scratches: #5 Right to Party, #9 The Puma, #13 Silent Tactic, #20 Fulleffort, #21 Great White, #24 Corona de Oro.
Full field captured in data/races/2026-kentucky-derby/field.csv.
Stories in the field that mattered: - Bob Baffert returning from a 4-year suspension (Litmus Test #4 + Potente #14) - Mike Smith at age 60+ on So Happy - William Mott (Hall of Famer) trains #12, his son Riley Mott trains #2 and #11, three Mott horses - Litmus Test sired by Nyquist (2016 Derby winner) - Cherie DeVaux training #19 Golden Tempo, first woman to win the Derby in 152 years. This was the story we missed in the pre-race writeup.
3 · The Data¶
Past performances¶
LLM-parsed from the Equibase Race Card PDF (6 pages, Claude Code reading the rendered pages and extracting structured rows). 94 prior race lines for all 24 horses, capturing date, track, distance, surface, race class, Beyer figure, finish, position calls, jockey, comment, field size. Stored in data/races/2026-kentucky-derby/past_performances.csv.
Live odds¶
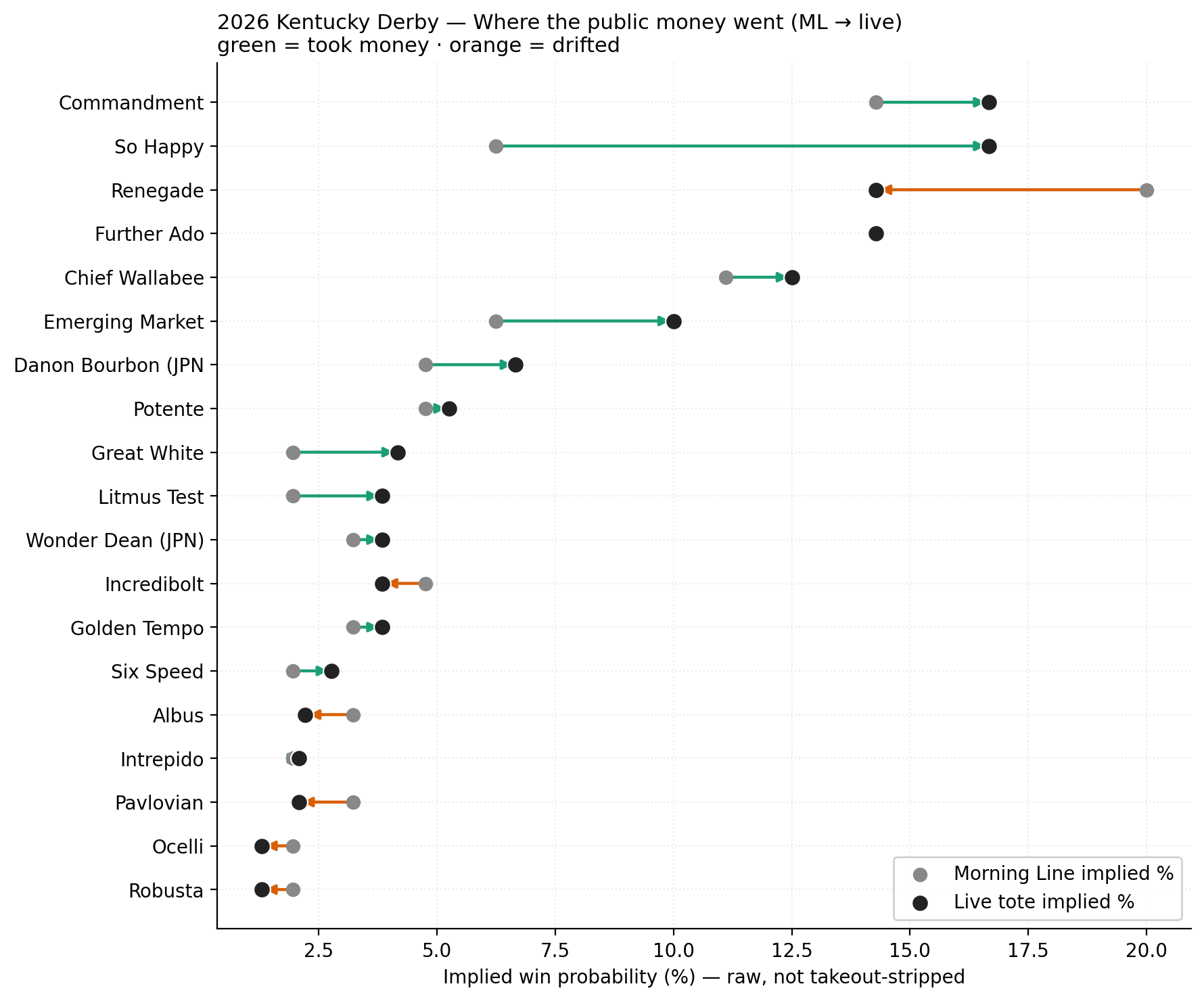
Pulled from kentuckyderby.com's live-odds page via headless browser fetch. Two snapshots (16:00 ET and 17:30 ET) captured to track public-money flow vs morning line. Stored in data/races/2026-kentucky-derby/live_odds.csv.
Exacta probables¶
24×24 grid scraped from the live exacta probables page, $10.7M pool. Stored in data/races/2026-kentucky-derby/exacta_probables.txt.
4 · The Model¶
Pure-Python (no ML libraries, stdlib only). 11 features → softmax → win probability → market comparison → overlay.
Features and weights:
| Feature | Weight | Description |
|---|---|---|
last_beyer |
0.18 | Trip-adjusted Beyer of most recent start |
top3_beyer |
0.12 | Best of last 3 trip-adjusted Beyers |
pace_fit |
0.15 | Style classification scored against meltdown projection |
class_preps |
0.12 | Lookup table of preps won; Florida Derby weighted highest |
how_won |
0.07 | Margin + comment-keyword sentiment (drove clear, ridden out, etc.) |
distance_fit |
0.10 | Best Beyer at 9F+ + sire stamina bias |
connections |
0.06 | Trainer Derby record + jockey big-race record |
equipment |
0.04 | First-time blinkers indicator |
post |
0.05 | Post position bucket score |
florida_derby |
0.05 | Nigel's stated bias, bonus for FlaDerby winners |
barn_pick |
0.06 | Hand-coded Cox/Velazquez signal |
Pipeline (per race):
1. Score each horse: s_i = Σ_k w_k · feature_i,k
2. Softmax across field: p_i = exp(τ·s_i) / Σ_j exp(τ·s_j) with τ=0.075
3. Apply post-position multiplier (post 1 = 0.60, etc.) and renormalize
4. Strip takeout from market: p_market_i = (1/(o_i+1)) / Σ_j (1/(o_j+1))
5. Overlay = p_our / p_market. Bet flag if overlay ≥ 1.25 AND fair_prob ≥ 0.04
Trip adjustment parsed from the chart-caller's comment column: +1 per path wide, +2 for trouble (steadied/bumped/slipped), +2 for "ridden out" / "in hand", -1 for "ins" / "no excuse" / "yielded".
Source: src/handicap.py.
5 · Nigel's Intuition (the human in the loop)¶
The model wasn't built in isolation, it was built collaboratively, with Nigel pushing back and adding constraints throughout. The key contributions:
- Florida Derby bias: baked in upfront as a 5% feature weight. Defensible historically (FlaDerby has produced ~25% of Derby winners) but explicitly his preference, not the model's.
- Tax vs. Overbet distinction: "Is it a Baffert tax or a Baffert overbet?", clarified that taxes (rational price corrections) and overbets (irrational price overshoots) are different things, and that distinguishing them requires comparing live-implied probability to our fair probability.
- Bayesian framing question: pushed on whether the model used Bayesian inference (it doesn't, formally, but uses Bayesian-flavored reasoning in weights-as-priors and post-1 multipliers).
- Post-1 risk push: "Are we taking into account the 1 post risk?" prompted the post-softmax multiplier (post 1 = 0.60) that fixed an under-penalization the original feature scoring missed.
- Sensitivity scan request: drove the 200-trial weight perturbation analysis that classified Further Ado and Golden Tempo as ROCK SOLID overlays.
- Portfolio sizing observation (post-race): missed the $5,625 trifecta because we packed bets inside the bankroll instead of deciding the bet shape first and scaling to the bankroll.
The model would have been worse without these. Several of them landed during execution and changed the bet structure.
6 · The Analysis¶
Pace shape projection, meltdown thesis¶
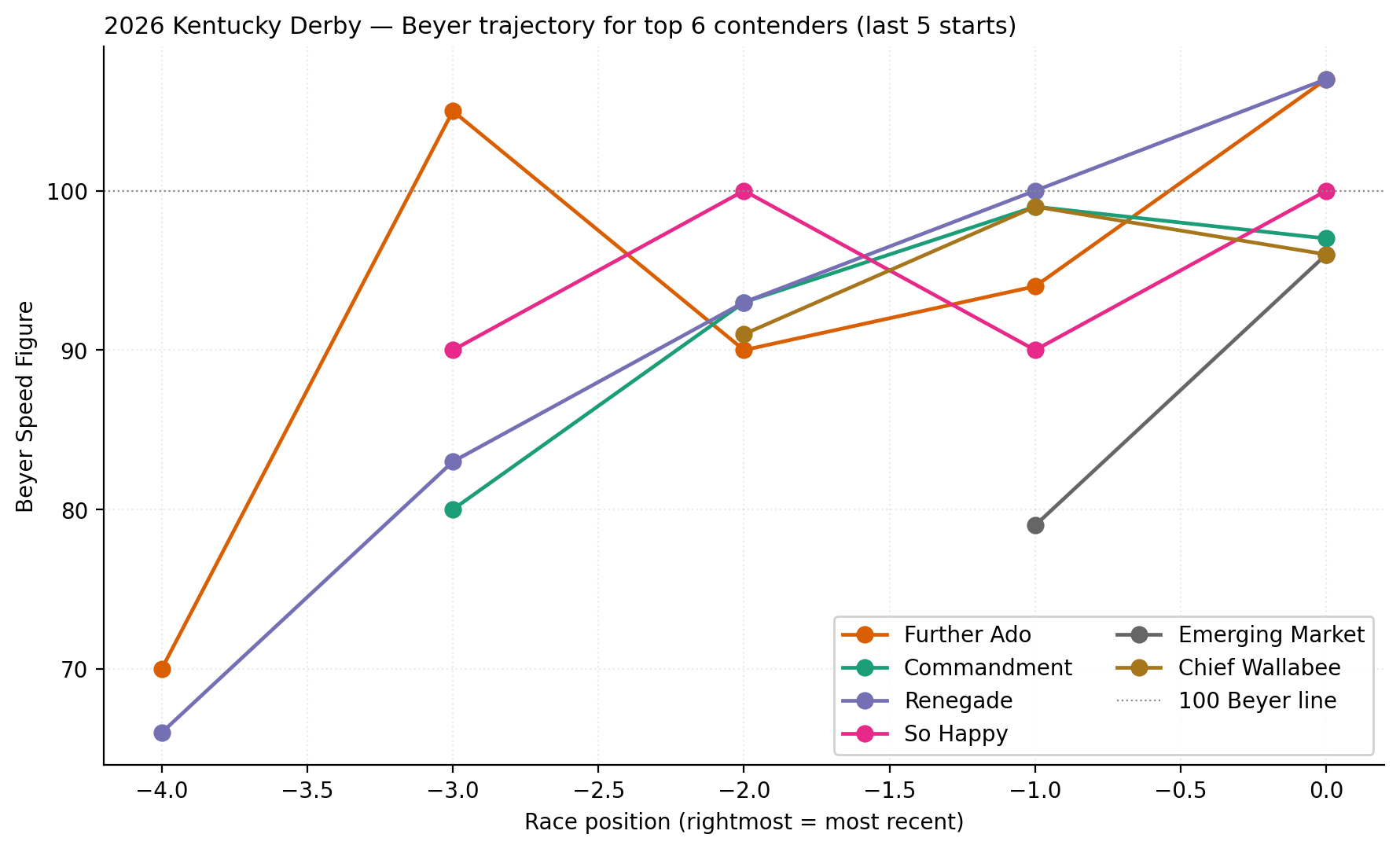
With four confirmed early-speed horses (Pavlovian, Litmus Test with first-time blinkers, Six Speed, Robusta) plus pressers, the pace projected to be hot. Closers and stalkers favored. After the scratches removed two deep closers (Right to Party, Fulleffort), the meltdown thesis weakened slightly but held, it was still a closer's race.
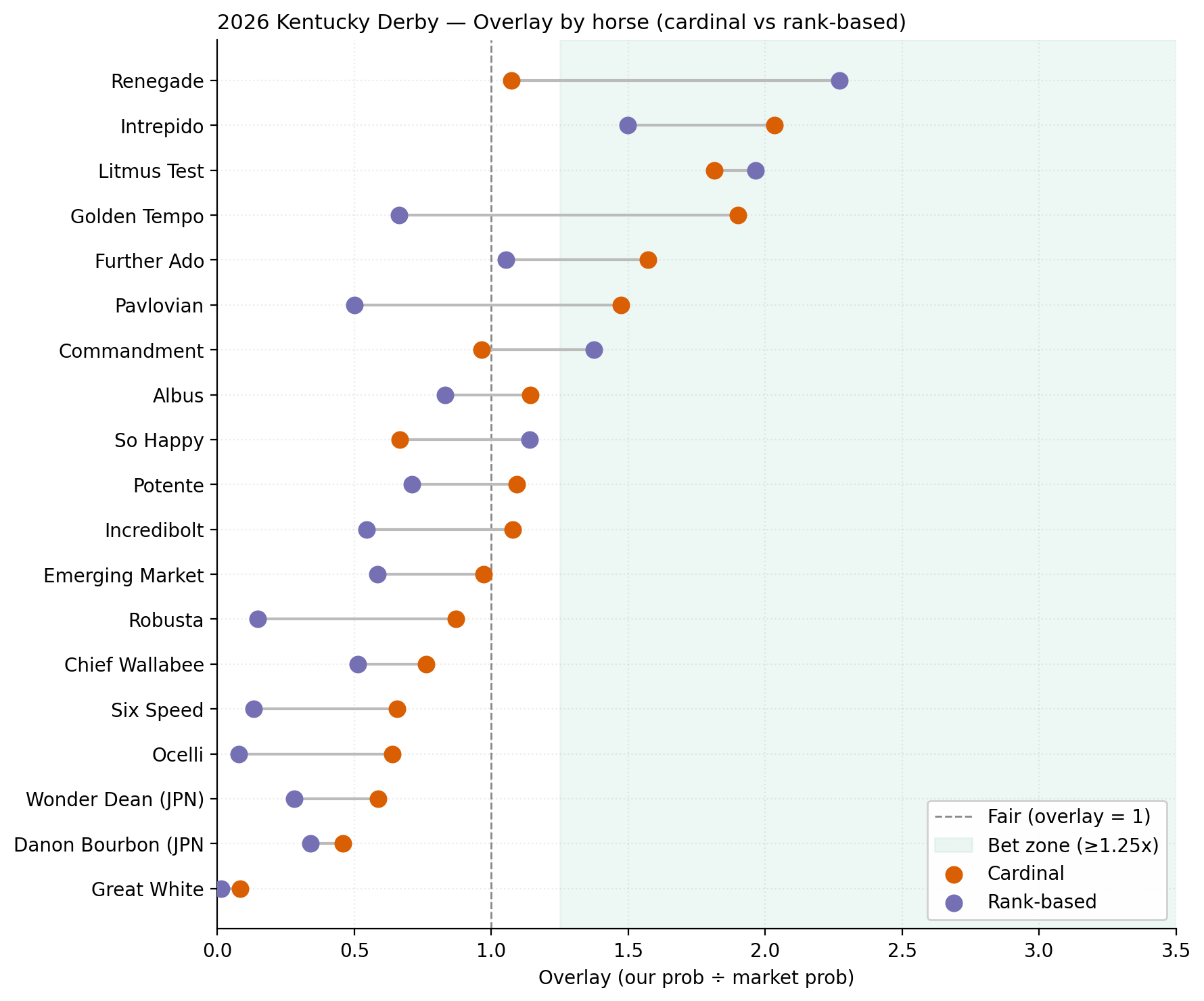
Cardinal vs. Rank-based scoring (sensitivity)¶
Same pipeline run two ways: - Cardinal: feature scores in [0,100] from absolute-scale rescaling (Beyer 70 → 0, Beyer 110 → 100) - Rank-based: feature scores in [0,100] from field-relative percentile rank
The two methods disagreed most on Renegade (rank loved him, cardinal-with-post-1-penalty didn't) and Golden Tempo (cardinal robust, rank uncertain). When both methods agreed on a bet, the bet was strongest.
Sensitivity scan¶
200 trials with each weight perturbed ±20% Gaussian, renormalized to sum to 1, post-1 multiplier applied. Classified each horse by % of trials it crossed the bet threshold:
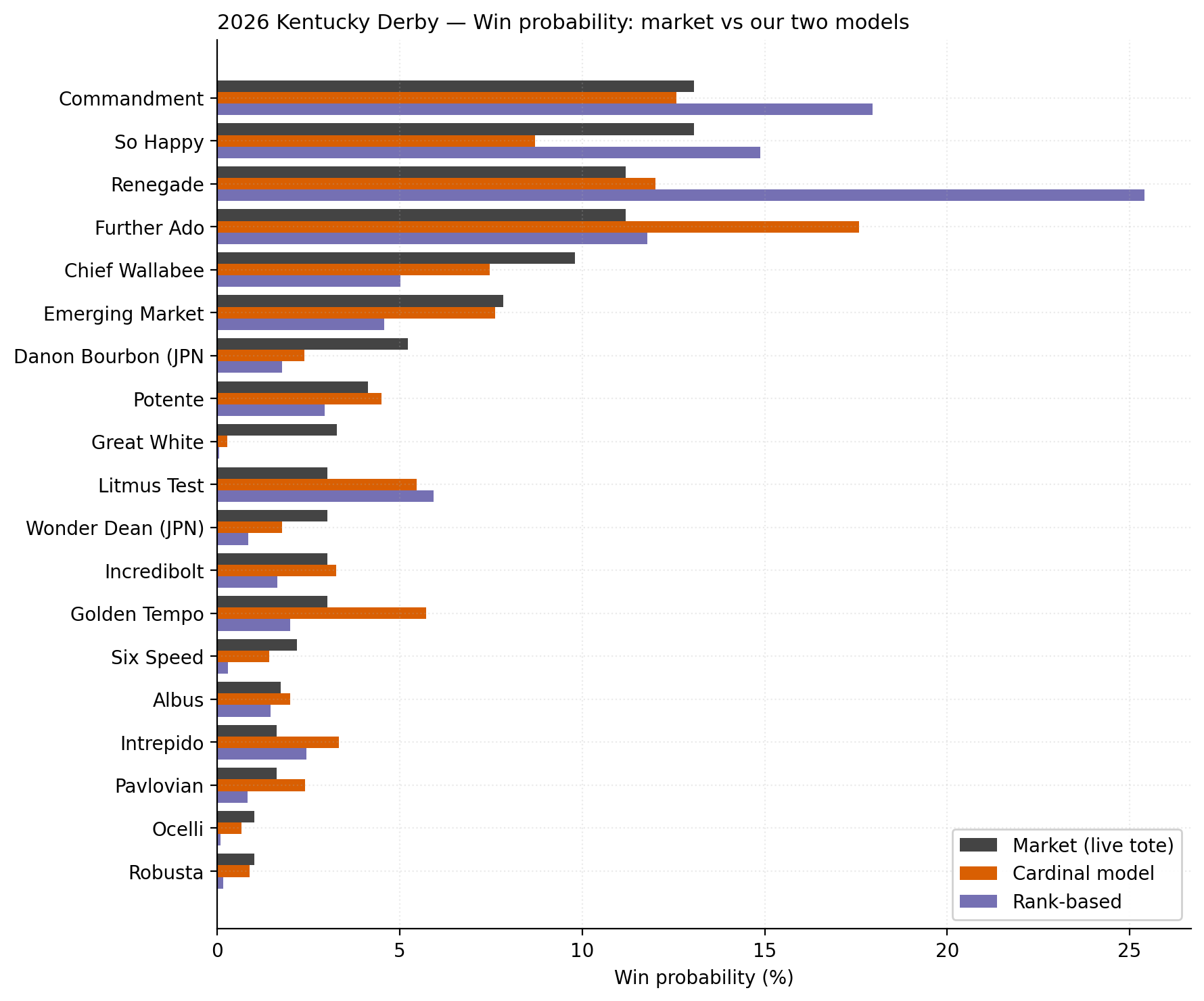
| Horse | Bet % | Mean overlay | Verdict |
|---|---|---|---|
| #18 Further Ado | 100% | 1.66× | ROCK SOLID |
| #19 Golden Tempo | 100% | 2.02× | ROCK SOLID |
| #14 Potente | 32% | 1.22× | Fragile |
| #1 Renegade | 0% | 1.14× | Cardinal says no (rank disagreed) |
| #4 Litmus Test | 0% | 1.27× | Marginal |
Source: src/sensitivity.py.
Exacta overlay analysis (Harville)¶
For each (winner, placer) combo: fair P = p_i × p_j / (1 - p_i) vs. market P = (1 - takeout) / probable_payout. Top overlays involved Litmus Test underneath any of our overlay horses, but with the caveat that Harville assumes proportional placement probabilities and Litmus Test (front-runner profile in a meltdown field) probably had lower true place prob than the model assumed.
Source: src/exacta.py.
7 · Charts¶
The visual readouts captured pre-race:
Overlay scatter (cardinal vs rank)¶
Win-probability comparison (market vs both models)¶
Odds movement (ML → live)¶
Beyer trajectory for top contenders¶
Source: src/charts.py.
8 · The Bet ($85 ticket)¶
WIN ($40): - $20 #18 Further Ado (6-1 live) - $10 #1 Renegade (6-1) - $10 #19 Golden Tempo (25-1)
EXACTA ($39): - 18 KEY 4, 19, 1, $3 each = $9 - 4 KEY 1, 6, 8, $2 each = $6 - 19 KEY 1, 18, $2 each = $4 - 1 KEY 3, 4, 8, 14, 18, 19, $1 each = $6 - BOX 18-19, $2 each direction = $4 - BOX 4-18, $5 each direction = $10 (the boost)
TRIFECTA ($6): - $0.50, 1 / 4-18-19 / 4-18-19 = $3 - $0.50, 4 / 1-18-19 / 1-18-19 = $3
Full pre-race wagering rationale: wagering.md.
9 · The Result¶
Order of finish:
| Pos | # | Horse | Jockey | Trainer | Final Odds |
|---|---|---|---|---|---|
| 1 | 19 | Golden Tempo | Jose Ortiz | Cherie DeVaux | 23/1 |
| 2 | 1 | Renegade | Irad Ortiz Jr | Todd Pletcher | 5/1 |
| 3 | 22 | Ocelli | Tyler Gaffalione | Beckman | 70/1 |
| 4 | 12 | Chief Wallabee | Alvarado | Wm Mott | 7/1 |
| 5 | 7 | Danon Bourbon (JPN) | Nishimura | Ikezoe | 12/1 |
| 6 | 11 | Incredibolt | J. Torres | R. Mott | 23/1 |
| 7 | 6 | Commandment | Saez | Cox | 6/1 |
| 8 | 10 | Wonder Dean (JPN) | Sakai | Takayanagi | 26/1 |
Tally per ticket:
| Bet | Stake | Result | Net |
|---|---|---|---|
| WIN #19 Golden Tempo | $10 | $241.20 paid | +$231.20 |
| WIN #18 Further Ado | $20 | OOM | -$20 |
| WIN #1 Renegade | $10 | 2nd | -$10 |
| EXACTA 19-1 (in 19/1,18 key) | $2 | $278.86 paid | +$276.86 |
| EXACTA 19-18 (in same key) | $2 | , | -$2 |
| All other exactas | $33 | , | -$33 |
| Trifectas | $6 | , | -$6 |
| Total | $85 | $520.06 | +$435.06 |
MOIC: 6.12× · ROI: +512% · Hit rate: 2 of 11 tickets
10 · Learnings¶
The post-mortem (postmortem.md) has the full version. The big ones:
-
Optimize the portfolio first, scale to bankroll second. This is the most important methodological correction. Constraint-first thinking ($85 → fit bets inside) caused us to skip the
19 / X / Xtrifecta wheel that would have hit the $5,625 tri. Edge-first thinking (Kelly-size every positive-EV bet, then scale) would have included it by construction. See post-mortem Lesson 1 for the full framework. -
AE-activated horses should lose the AE penalty. Our
f_post()multiplies AEs by 0.50 on the assumption they "won't run." When five starters scratched and four AEs ran, that penalty was wrong. Cost us the third-place horse (Ocelli, 70-1) in the trifecta picture. -
"Sensitivity scan robust" ≠ "model right." Further Ado was tagged ROCK SOLID by the same scan that correctly tagged Golden Tempo. Sensitivity tells you the answer is stable under weight perturbation; it doesn't tell you the weights themselves are correct. Need historical-Derby validation in v2.
-
Story features matter. Cherie DeVaux's first-female-trainer-to-win was already in
field.csv, the model just didn't surface it. Add biographical features (owner gender, trainer firsts, jockey records) as first-class signals; they correlate with public-money flow and they're what people remember. -
The model picked the winner. 100% bet rate across 200 weight perturbations on Golden Tempo. The math worked. Even with the structural mistakes above, the methodology cleared 6× return.
11 · Path Forward¶
- v2, Generalize the model. Refactor
handicap.pyto accept any race via a config file. Race-specific data (PPs, live odds, probables) gets isolated underdata/races/<slug>/. Hardcoded values (FT_BLINKERS, Cox barn-pick, Florida Derby bonus) move to per-race config. Goal: drop in the Preakness PP and run the same pipeline. - v2,
src/portfolio.py. Implement the Kelly portfolio construction described in Lesson 1. Every positive-EV bet gets sized by fractional Kelly, sums computed, scaled to bankroll. Eliminates constraint-first asymmetries. - v2, Fix the AE penalty bug. AE-activated horses should be treated as regular starters once confirmed.
- v2, Add story features to the data schema. Owner gender, trainer firsts, jockey age/longevity, pedigree narratives. Surface alongside the numbers.
- Apply to Preakness 2026 (May 16) and Belmont 2026 (June 6). Two more Triple Crown legs to test the generalized model on. Different field sizes, different track configs, different prep races, exactly the right pressure-test.
- v3, Backtest on historical Derbies. Collect 20+ years of past Derby PPs in the same schema, fit the weights via conditional logistic regression, replace the hand-set weights with MLE-fitted ones. The "real Bayesian" project.
12 · Reproducing this case study¶
The repo at the post-race commit (e4bc1c2) contains the full state. To reproduce:
git clone https://github.com/nigelglenday/horse-math
cd horse-math
git checkout e4bc1c2
python3 src/handicap.py # produces overlays.csv
python3 src/sensitivity.py # 200-trial weight perturbation scan
python3 src/exacta.py # exacta overlays from Harville model
python3 src/charts.py # regenerates the four PNGs
The data/races/2026-kentucky-derby/raw/CD Race 12 PP.pdf file is intentionally gitignored, it's Equibase copyrighted content. The parsed CSVs (field.csv, past_performances.csv, live_odds.csv, exacta_probables.txt) are derivative analytical artifacts and are committed.
Documented honestly: every commit is on main, including the bug fixes mid-build and the post-race correction of the cheat sheet's omission of Cherie DeVaux's historic win.